SEO & Marketing
File robots.txt là gì? Cách để tránh việc đối thủ làm giảm chất lượng Website của bạn

Bạn đã cấu hình file robots.txt của mình đúng hay chưa? Bài viết này sẽ giúp bạn có một cái nhìn đúng về robots.txt là gì? và cấu hình cho phù hợp, hạn chế việc đối thủ khai thác nhằm hạ điểm chất lượng website của bạn. 
File robots.txt là gì ?
Tệp robots.txt là một tệp ở gốc trang web của bạn cho biết những phần thuộc trang web bạn không muốn cấp quyền truy cập cho trình thu thập dữ liệu của công cụ tìm kiếm. Đây là file đầu tiên mà Google Bot sẽ đọc khi truy cập Website của bạn. File robots.txt bao gồm giao thức là một tệp nhỏ các lệnh để quy định cho các cỗ máy tìm kiếm dữ liệu được phép hoặc không được phép thu thập dữ liệu trong website của bạn.File robots.txt để làm gì?
Cho phép hoặc hạn chế Google Bot (hay các công cụ thu thập dữ liệu khác như Cốc Cốc Bot, Bing bot, Ahrefs...) được phép lập chỉ mục, thu thập dữ liệu Website của bạn. Robots.txt được sử dụng để kiểm soát lưu lượng truy cập của Bot, hạn chế các trang kém chất lượng, ẩn website khỏi công cụ tìm kiếm...Các tệp lệnh nhỏ trong file robots.txt bạn cần biết
File robots.txt được nằm ở thư mục gốc của Website. Để kiểm tra website của bạn có file robots.txt hay chưa bạn chỉ cần thêm /robots.txt vào sau tên miền của bạn. Nếu có thể truy cập được thì Website đã có robots.txt . Nếu Website chưa có thì bạn chỉ cần tạo file này trên máy tính và gửi cho người code trang web. VD: /robots.txt Một số tệp lệnh nhỏ trong file robots.txt- User-agent: Tên loại bot
- Allow: Cho phép
- Disallow: Không cho phép
- Sitemap: Đường dẫn sơ đồ của trang web.
- Ghi chú: Dấu * thay cho chuỗi, có nghĩa là áp dụng với tất cả. Mỗi công cụ thu thập dữ liệu đều có một cái tên như googlebot, bingbot, coccocbot... nếu muốn chặn một loại bot cụ thể chúng ta sẽ khai báo tên cụ thể của loại bot đó.
Các trường hợp cụ thể sử dụng file robots.txt
Robots.txt bao gồm các tệp lệnh, chỉ sử dụng để chặn các trang có cấu trúc về đường dẫn tương đồng.1.Sử dụng file robots.txt để chặn Google (trong quá trình webiste đang xây dựng)
Trong quá trình bạn đang hoàn thiện website, cụ thể là website trong giai đoạn demo, chưa có nội dung, chưa tối ưu nội dung, hình ảnh, cấu trúc... thì bạn nên chặn Google lập chỉ mục trong thời gian này. Cấu trúc file robots.txt như sauUser-agent: * Disallow: /2. Sử dụng file robots.txt để quy định nội dung nào được lập chỉ mục, nội dung nào không được lập chỉ mục.
VD: Tú có 1 website là domain.com và có 2 danh mục Apple (domain.com/apple) và Samsung (domain.com/samsung).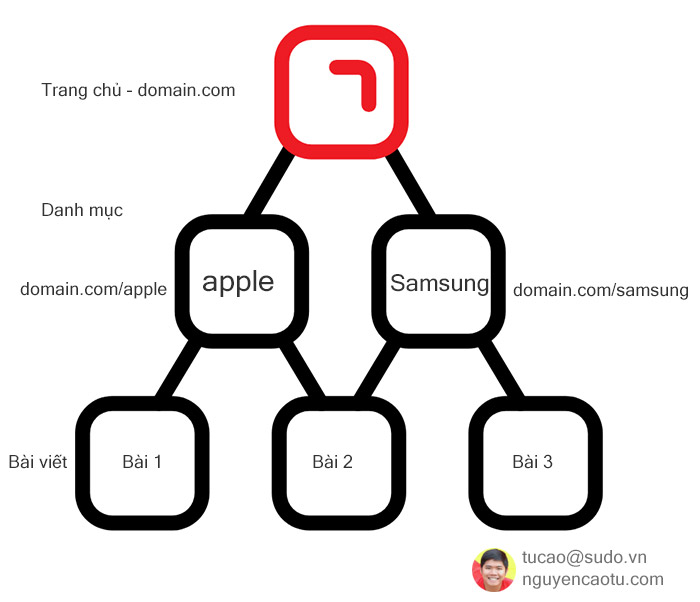
User-agent: * Disallow: /samsung3. Sử dụng robot.txt để chặn những trang kém chất lượng, nội dung tự tạo
Phổ biến nhất là trang tìm kiếm trên mỗi Website. Trang này có nội dung kém chất lượng và bất kỳ ai đều có tự tạo nội dung ở đây. Bất kỳ từ khóa nào người dùng tìm kiếm khi gõ vào ô tìm kiếm đều được hiển thị trên Website của bạn. Vậy sẽ ra sao nếu đối thủ họ đưa các từ khóa nhạy cảm, từ khóa cấm vào website của bạn và họ xây dựng các backlink về những liên kết đó ?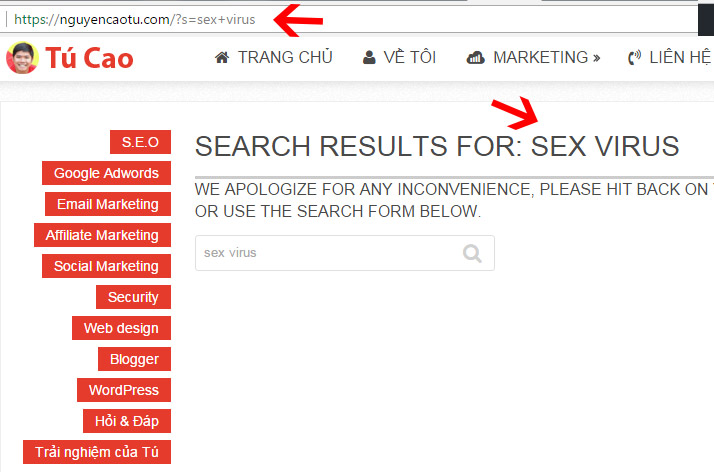
User-agent: * Disallow: /?s=4. Sử dụng để chặn google index và lộ link các file download trả phí
Một số các trang web có tải lên các file pdf để người dùng tải về, thông thường các file này rất nặng sẽ gây tốn tài nguyên cho Website. Hoặc một số Website cho phép tải file trả phí nhưng ko dấu đường link download cũng có thể Google sẽ index các nội dung này. Lời nguyên tốt nhất là đừng tải file nào nặng lên Website (hacker có thể tấn công website sẽ rất nhanh bị hạ gục). Hoặc bạn có thể chặn theo cách sau để hạn chếUser-agent: * Disallow: *.pdf5. Sử dụng để chặn các công cụ thu thập liên kết (như Ahrefs)
Để đảm bảo an toàn cho các website vệ tinh tránh việc đối thủ nhòm ngó và biết được hệ thống của bạn, bạn nên chặn tất cả các công cụ quét liên kết (đặc biệt là ahrefs.com - công cụ check backlink lớn nhất hiện tại). Lưu ý: Robots.txt không chặn dược các liên kết (link) tham chiếu tới Website của bạn. Để chặn ahrefs bạn cần đặt file robots.txt này trên các website vệ tinh.User-agent: AhrefsBot Disallow: / 6. Chặn phần phân trang trong wordpress
Rất nhiều bạn sử dụng Wordpress, bạn để ý ở những danh mục có nhiều bài viết thì Wordpress sẽ phân trang. Những trang con chúng ta luôn bị trùng lặp title, description và thường là không SEO các trang này. Vì thế cách tốt nhất hãy chặn nó đi, tránh để google báo cáo dữ liệu chúng ta có những trang kém chất lượng, trùng lặp title, description. VD: Danh mục iPad của Website này có phần trang. Tú không seo các page2, page3 của nó nên mình chặn.- https://thanhtrungmobile.com/sua-chua/sua-chua-apple/ipad
- https://thanhtrungmobile.com/sua-chua/sua-chua-apple/ipad/page/2
User-agent: * Allow:/ Disallow: */page/ Sitemap: https://thanhtrungmobile.com/sitemap.xml7. Không chặn css, javascript
Update 29/5/2019. Theo tài liệu chính thức của Google thì việc bạn chặn css, javascript có thể khiến Google bot không thể hiểu cách bạn hiển thị cho người dùng. Do đo tuyệt đối không chặn các tệp này.Cấu trúc của 1 file robots.txt chuẩn bao gồm
Lưu ý: bạn cần chỉnh sửa cho phù hợp với Website của bạn. (thay đổi lại url tìm kiếm và link tới sitemap)User-agent: * Allow: / Disallow: /tim-kiem/ Sitemap: https://domain.com/sitemap.xmlChúc bạn thành công !
5.0
251 Đánh giá 
Tác giả có 10 năm kinh nghiệm về thiết kế Website và SEO. Tôi hiện là CEO của Sudo - một công ty chuyên về xây dựng trang Web cho cá nhân và doanh nghiệp.